Service for Implementation on Edge Devices
We design processing architectures optimized for the target hardware from pre-trained algorithms, enabling high-speed execution on edge devices.
Simply provide us with the algorithm you've developed, and we'll read and understand the contents to devise an architecture that's suitable for the algorithm. Our solutions are compatible with various frameworks, including Caffe, Keras, TensorFlow, and PyTorch. Leveraging decades of experience in digital circuit design and embedded software development, we provide optimal solutions without burdening our clients.Service for Implementation on Edge Devices
To implement algorithms on devices such as FPGAs and GPUs at the edge, it is necessary to have a thorough understanding of the characteristics and resources of the target devices, and in some cases, architectural design or network optimization may be required.
At our company, we leverage our experience in implementing FPGAs, GPUs (Jetson AGX Xavier), as well as AI chips such as TPU (Google TPU) and VPU (Intel Movidius Myriad X VPU), to meet our customers' needs from device selection to implementation.
We can demonstrate the implementation of a lightweight semantic segmentation network on various edge devices by showcasing its performance.
At our company, we leverage our experience in implementing FPGAs, GPUs (Jetson AGX Xavier), as well as AI chips such as TPU (Google TPU) and VPU (Intel Movidius Myriad X VPU), to meet our customers' needs from device selection to implementation.
We can demonstrate the implementation of a lightweight semantic segmentation network on various edge devices by showcasing its performance.
Demo 1: High-speed execution of semantic segmentation using FPGA (Zynq UltraScale+)
We would like to introduce a demonstration of real-time semantic segmentation being performed on input from a USB camera.
List of classes

List of classes
At our company, we have implemented semantic segmentation algorithms on FPGAs and achieved high-speed processing of 40fps.


- Capturing the video displayed on the monitor from the drive recorder using a USB camera.
- Transferring the USB camera image from ARM to FPGA for performing semantic segmentation inference.
- Transferring the inference result from FPGA to ARM and outputting it to the monitor together with the input image.
| Implemented Algorithm and Target Device |
|---|
| Algorithm: PixelNet (http://www.cs.cmu.edu/~aayushb/pixelNet/) Target Board: ZCU102 (featuring the Xilinx Zynq UltraScale+ ZU9EG) Our company has adapted the above algorithm for FPGA and retrained it by modifying its network configuration. For further information, please refer to "Algorithm Design: Semantic Segmentation". |
| Processing Time |
| 40fps |
| Number of Classes |
| 22 classes, including roads, white lines, cars, pedestrians, etc. |
Demo 2: Comparison of Lightweight PixelNet Implemented on Edge Devices - Inference Execution on Zynq (FPGA), Jetson (GPU), and TPU
In a similar manner to Demo 1, we implemented a lightweight version of PixelNet on different edge devices and compared their inference execution.
| Edge Devices | ZCU102 | Jetson AGX Xavier | Coral Dev Board | Coral USB Accelerator |
|---|---|---|---|---|
| Manufacturer | Xilinx | NVIDIA | ||
| Accelerator | FPGA | GPU @ 1.4 GHz DL accelerator | Edge-TPU | |
| Processing Capability | 11 + 5 TFLOPS (FP16) 22 + 10 TOPS (INT8) |
4TOPS | ||
| CPU | ARM Cortex-A53 (4-core) | ARM v8.2 64-bit CPU (8-core) | ARM Cortex-A53 (4-core) | |
| Data Width at Implementation Time | INT16 | FLOAT32 | INT8 | |
| Actual Device Image |  |
 |
 |
 |
In the demo video, images saved on the SD card of each edge device are read out one by one, and inference is performed immediately.
Let me introduce each edge device.
Let me introduce each edge device.
ZCU102
It is an FPGA board with a chip called ZU9EG, which is a Zynq UltraScale+.The board has an SoC (System on Chip) configuration with both ARM and FPGA components.
Real-time processing was demonstrated in the demo video, thanks to the optimal processing architecture that we developed in-house and implemented on the FPGA. This allowed segmentation to be executed at a processing speed of 40fps.
Jetson AGX Xavier
This module features an Nvidia GPU and an ARM CPU.The demo video showcases the use of the TensorFlow framework to perform inference on the GPU, achieving a segmentation processing speed of 13-15fps.
Coral Dev Board
This board features Google's Edge TPU.It has an SoM (System on Module) configuration with both NXP i.MX 8M SoC and the Edge TPU.
In the demo video, inference was performed on the Edge TPU using a model that had been converted to TensorFlow Lite.
Segmentation was achieved at a processing speed of 17-20fps.
The choppy demo screen in the video is caused by the heavy drawing processing on the ARM mounted on the NXP i.MX 8M.
Coral USB Accelerator
This is a USB accelerator with Google's Edge TPU onboard.In the demo video, inference was executed on the Edge TPU with a model converted to TensorFlow Lite.
As it is a USB accelerator, other devices are required for transferring input images and drawing inference results.
In the demo video, Jetson nano was used.
Segmentation was able to be performed at a processing speed of 8-10fps.
Example of Implementation Process for Edge Devices
As part of our demo creation, we will showcase the implementation process for edge devices. Our company handled the entire process, which included annotation, algorithm design for lightweighting, retraining, and implementation to the edge device.
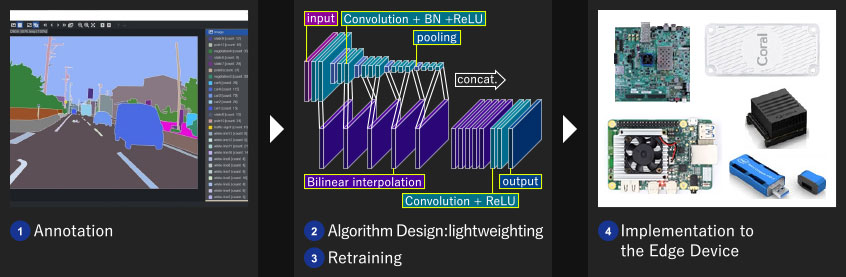
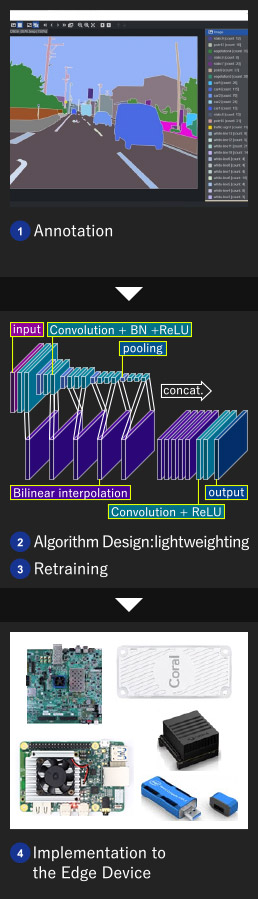
- In the demo, we used road images from Hamamatsu city that we acquired and annotated in-house.
For more information about our annotation services, please refer to our "Annotation" page. - To implement the model on edge devices, we independently optimized PixelNet for lightweight performance.
For more details on our optimization process, please see our "Algorithm Design: Semantic Segmentation" page. - We retrained the network using Python code with the lightweight version.
- We adjusted the data width for each device and implemented the model on all edge devices.
In the next section, "Implementation Points for High-Speed Execution on Edge Devices," we will introduce the key considerations for implementing the model on edge devices to ensure high-speed execution.
Implementation Points for High-speed Execution on Edge Devices
At our company, we design the optimal architecture to achieve high-speed execution tailored to the customer's requirements as well as the target device and algorithm.
For example, when implementing on FPGA, key points include improving throughput by pipeline processing and parallelizing output channels in each processing layer.
Here, we'll introduce how to improve throughput using pipeline processing.
When we consider a CNN with Conv (3x3) -> Conv (3x3) -> MaxPooling (2x2), as shown in the diagram below, processing for the next stage, Conv1_2, starts once three rows of feature values are output from the previous stage, Conv1_1. Similarly, for MaxPooling, processing for the next stage starts once two rows of feature values are input from Conv1_2. By building such a pipeline, it's possible to improve the throughput of the algorithm as a whole.
For example, when implementing on FPGA, key points include improving throughput by pipeline processing and parallelizing output channels in each processing layer.
Here, we'll introduce how to improve throughput using pipeline processing.
When we consider a CNN with Conv (3x3) -> Conv (3x3) -> MaxPooling (2x2), as shown in the diagram below, processing for the next stage, Conv1_2, starts once three rows of feature values are output from the previous stage, Conv1_1. Similarly, for MaxPooling, processing for the next stage starts once two rows of feature values are input from Conv1_2. By building such a pipeline, it's possible to improve the throughput of the algorithm as a whole.

Development Achievements
Pose Estimation
We implemented the customer's development algorithm on Zynq and developed a demo system for end-users.General Object Detection
Development of implementation environment using SDSoC (Xilinx high-level synthesis tool) and initial implementation on Zynq.Area Division for Automotive Use
Investigation of deployment targeting FPGAs, TPUs, and VPUs for an algorithm that performs segmentation.Development Process
-
01
Pre-trained Algorithm
(provided by the customer) -
02
Device Selection -
03
Architecture Design -
04
Code Development and Testing -
05
Verification of Operation on Actual Device
(including processing time)
01Trained Algorithms (Provided by the Customer)
We also provide algorithm development services at our company. Depending on the issues and requests our customers have, we can provide solutions ranging from algorithm research and design to implementation.
02Device Selection
We'll work with you to understand your unique requirements and provide you with customized device recommendations that will meet your specific needs, including factors such as cost and power consumption.
03Architecture Design
We have a deep understanding of device characteristics and can design an architecture that achieves the desired processing time while estimating the required logic resources. Depending on the situation, we may also perform lightweight network analysis for device implementation.
For example, we may extract bottleneck processing in order to optimize network performance.
For example, we may extract bottleneck processing in order to optimize network performance.
04Code Creation and Verification
We create code that adheres to the proposed architecture, and then use tools to estimate the usage of logic resources and processing time. We also conduct an equivalence verification by comparing expected values. Through an iterative process of re-examining the architecture, modifying and verifying the code, we aim to implement it on the target device.
05We will Perform Operational Testing (processing time, etc.) on the Actual Machine.
We will implement the code built with the tool on the actual machine and evaluate the processing time and accuracy on the machine.
Partner

SANEI HYTECHS is a sensAI design service partner certified by Lattice Semiconductor.

SANEI HYTECHS is an Adaptive Computing Partner of AMD.