Edge Computing (implementation of artificial intelligence)
Development of AI implementation technology through edge computing
Generally, artificial intelligence algorithms are designed using high-performance machines, and AI designers are responsible for creating software that runs on those machines. On the other hand, AI is ultimately expected to be installed on mobile devices such as robots and cars.SANEI HYTECHS is refining the technology to implement artificial intelligence on target devices, drawing on the concept of "edge computing," which processes tasks on microcontrollers and FPGAs at the edge of the entire network system, previously done on high-performance machines.
Research and development of AI implementation services
In addition to designing artificial intelligence, we are also advancing the development of "AI implementation services." Generally, AI algorithms are designed using high-performance machines, and AI designers are responsible for creating software that runs on those machines. On the other hand, AI is ultimately expected to be installed on mobile devices such as robots and cars. It would be ideal to simply mount the high-performance machines on the mobile devices, but this is not realistic due to the weight and size of the machines significantly impairing the mobility of the devices. The idea of connecting to external high-performance machines via wireless communication exists, but with this method, the delay caused by communication can become a bottleneck, slowing down the overall processing speed of the system and rendering the intelligent AI algorithm practically unusable.
The concept of edge computing
What is required is to implement some or all of the AI algorithms on "microcontrollers" or "FPGAs." Microcontrollers and FPGAs are connected to high-performance machines via communication, processing real-time necessary parts with microcontrollers and FPGAs, and processing delay-allowed parts with high-performance machines. This concept of "edge computing," which processes tasks on microcontrollers and FPGAs at the edge of the entire network system that were previously done on high-performance machines, is gaining traction, and our company is also refining its implementation technology. To implement AI algorithms on edge devices, it is necessary to lighten the algorithms to a form that can be mounted on microcontrollers and FPGAs, and to appropriately divide the processing content between software and digital circuits. Of course, mastering the use of devices is also a fundamental technology required.
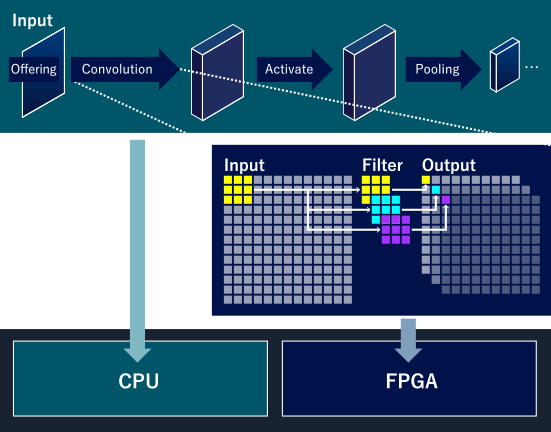
Implementing CNN on CPU and FPGA
Implementation technology for mounting neural networks on Zynq
Our company is working on acquiring implementation technology while accumulating achievements such as mounting neural networks, as shown in the separate item "AI Design - Deep Learning," on Xilinx's Zynq (please refer to "Co-design of Digital and Soft - Zynq and Intel SoC" for the development of systems using Zynq).
Efforts Toward Lightweighting
To make neural networks lightweight so they can be mounted on target devices like Zynq, we first estimate the resources consumed when performing calculations with the same accuracy as high-performance machines. For example, the amount of memory required to hold each coefficient in the neural network (size of registers), the scale of digital circuits needed to implement the main operation unit on FPGA (amount of DFF and lookup tables), etc. In parallel, we calculate the processing time (latency and throughput) based on several assumptions. CNN-style neural networks contain a large number of summation operations that can be parallelized in digital circuits, so the processing time is related to the trade-off with the number of parallel operations (i.e., the scale of digital circuits).
Evaluating Resources
Based on the estimated values, we consider how much resources should be reduced to mount the neural network on the target device. In particular, determining the bit width of the calculations is essential. When parallelizing with digital circuits, calculations are performed in fixed-point rather than floating-point, so we first convert the neural network's calculations to fixed-point. Then, we check the error in the output results of the neural network caused by the fixed-point conversion. For example, in the case of a neural network that detects the centerline of a road from road images, we input the road image to the fixed-point neural network and output the centerline position information.
The difference between this value and the floating-point calculation result obtained using a high-performance machine corresponds to the error. The final bit width is determined based on the trade-off relationship between this error and the resource amount determined by the bit width.
However, to achieve the bit width that meets the accuracy of the specifications, it may be necessary to use an amount of resources that cannot fit on the target device. In this case, we go back to the AI design phase, review the neural network configuration, and redo the deep learning process.
The difference between this value and the floating-point calculation result obtained using a high-performance machine corresponds to the error. The final bit width is determined based on the trade-off relationship between this error and the resource amount determined by the bit width.
However, to achieve the bit width that meets the accuracy of the specifications, it may be necessary to use an amount of resources that cannot fit on the target device. In this case, we go back to the AI design phase, review the neural network configuration, and redo the deep learning process.
Implementation
Once you have a clear idea of the resource volume and processing time, you can proceed to the actual implementation.
Using high-level synthesis tools like Xilinx's SDSoC, you can generate digital circuits. If the size and latency of the generated digital circuit become too large compared to the initial estimates, you will need to design the RTL manually.
Using high-level synthesis tools like Xilinx's SDSoC, you can generate digital circuits. If the size and latency of the generated digital circuit become too large compared to the initial estimates, you will need to design the RTL manually.
High-level synthesis tool: SDSoC
As mentioned above, the specific implementation flow is almost the same as in general systems. However, to understand the trade-off relationship and make appropriate decisions, it is essential for the person responsible for the implementation to have a good understanding of artificial intelligence. Also, if the target performance cannot be achieved, the decision to go back to the AI design phase or not will largely depend on the person in charge of the implementation.