アルゴリズム設計
ゼロベースからのネットワーク設計から開発サポートやコンサルティングまで幅広いニーズに応えます。
三栄ハイテックスは、独自の人工知能(AI)研究で培った知見を背景に、お客さまのニーズに応じたさまざまなアルゴリズム設計サービスを提供します。フルスクラッチ設計から開発サポート、エッジデバイスを見据えたネットワークの軽量化検討などお客さまのご要望にフレキシブルに対応可能です。INDEX
アルゴリズム設計サービス
アルゴリズムのフルスクラッチ設計
用途に応じてニューラルネットワークの構成やそれ以外のアルゴリズムをゼロベースで設計
アルゴリズムのブラッシュアップ
お客さまの初期アイデアをベースに、アルゴリズムを高精度化/軽量化
伴走型開発
論文の調査からアルゴリズム設計、デバイス実装に向けた検討まで、お客さまと一体で推進
設計実績
大手自動車関連会社様、大手電機メーカー様、画像関連企業様など、多様な分野のお客さまへのサービス実績があります。
主な業務実績
セグメンテーションアルゴリズム開発、学習用環境の提供とサポート(コンサルティング)
セグメンテーションアルゴリズム開発、学習用環境の提供とサポート(コンサルティング)
セマンティックセグメンテーション
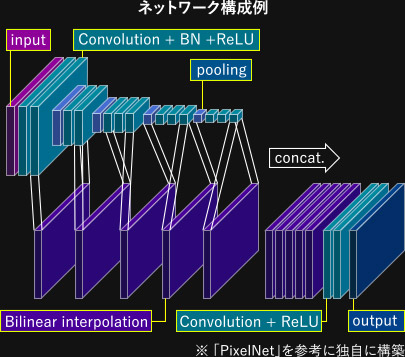
FPGAやMPUでセマンティックセグメンテーションアルゴリズムを実装できるよう、PixelNetをターゲットとして軽量化しました。
これらの手法により、パラメータ数を9割削減しました。
また、軽量化後、再学習と評価を行い、軽量化前と比較しても精度(mIoU)に大きく差が無いことを確認できました。
さらに、FPGAやMPUへ実装するために、軽量化したPixelNetをハードウエア向けに最適化しました。
実装した結果については、「エッジデバイス実装:デモ:FPGA(Zynq UltraScale+)でセマンティックセグメンテーションの高速実行」もご参照ください。
- 入力画像サイズの縮小
- 各処理層における入出力ch数を削減(例 Convolution層の入出力ch:512ch⇒32ch) など
これらの手法により、パラメータ数を9割削減しました。
また、軽量化後、再学習と評価を行い、軽量化前と比較しても精度(mIoU)に大きく差が無いことを確認できました。
さらに、FPGAやMPUへ実装するために、軽量化したPixelNetをハードウエア向けに最適化しました。
- パラメータを16bit固定小数点化
- 後段でのConvolution層の処理をBilinear interpolation直後に行うように分割 など
実装した結果については、「エッジデバイス実装:デモ:FPGA(Zynq UltraScale+)でセマンティックセグメンテーションの高速実行」もご参照ください。

その他、設計可能なアルゴリズムの一例
当社では、画像解析や音声分析をさまざまな用途・デバイスを想定したアルゴリズムを研究しています。
詳しくは研究開発のページをご覧ください。
詳しくは研究開発のページをご覧ください。
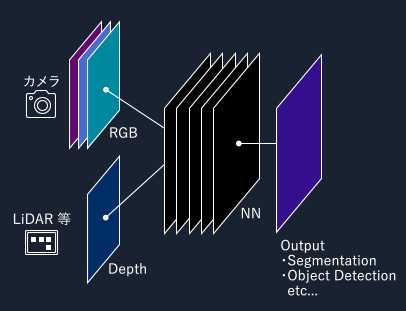
RGB 画像に距離(Depth)データを追加
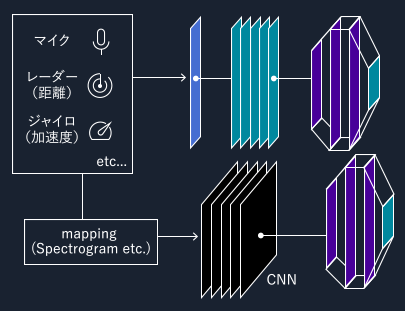
マルチモーダルなシステム設計