エッジコンピューティング(人工知能の実装)
エッジコンピューティングによる、人工知能の実装技術開発
一般的に、人工知能のアルゴリズムは演算能力の高いマシンを使って設計され、人工知能の設計者は、高性能マシンの上で動くソフトウェアを作るところまでの役割を担います。その一方で、人工知能は最終的にロボットや車などの移動装置に搭載されることが期待されています。 三栄ハイテックスは、高性能マシンで行っていた処理をネットワークシステム全体の先端(エッジ)に位置するマイコンやFPGAで処理する「エッジコンピューティング」の発想で、人工知能をターゲットデバイスに実装する技術を磨いています。人工知能の実装サービスの研究開発
人工知能の設計に加え、「人工知能の実装サービス」の開発も進めています。一般的に、人工知能のアルゴリズムは演算能力の高いマシンを使って設計され、人工知能の設計者は、高性能マシンの上で動くソフトウェアを作るところまでの役割を担います。その一方で、人工知能は、最終的にはロボットや車などの移動装置に搭載されることが期待されています。高性能マシンを移動装置にそのまま載せられればよいのですが、マシンの重さやサイズによって装置の移動能力を著しく損なってしまうため現実的ではありません。無線通信によって外部の高性能マシンと接続するという発想もありますが、この方法ですと、通信による遅延時間がボトルネックになってシステム全体の処理速度を低下させ、せっかく作った賢い人工知能アルゴリズムを実用に全く耐えられない程度のスピードでしか実行できない結果になりかねません。
エッジコンピューティングの発想
そこで求められるのが、人工知能のアルゴリズムの一部あるいは全体を「マイコン」や「FPGA」で実現することです。マイコン・FPGAと高性能マシンを通信によって接続して、リアルタイム性が必要になる部分をマイコン・FPGAで処理し、遅延が許される部分を高性能マシンで処理します。このような、高性能マシンで行っていた処理をネットワークシステム全体の先端(エッジ)に位置するマイコンやFPGAにて処理する、という「エッジコンピューティング」の発想が広がりつつあり、当社でもその実装技術を磨いています。エッジのデバイスへ人工知能のアルゴリズムを実装するためには、アルゴリズムをマイコンやFPGAに搭載可能な形に軽量化し、処理の内容をソフトウエアとデジタル回路に適切に分割する技術が必要になります。もちろん、デバイスを使いこなすことも基盤技術として求められます。
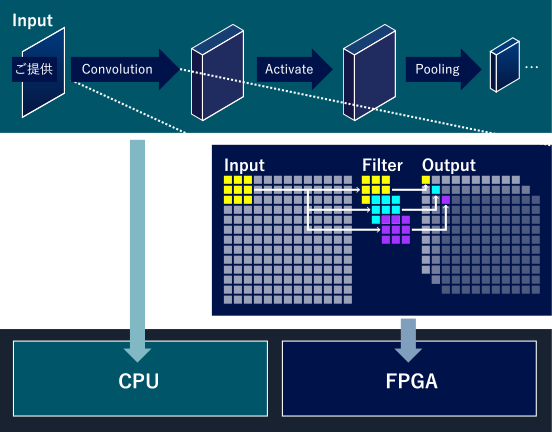
CNNをCPUとFPGAへ実装
ニューラルネットワークをZynqへ搭載する実装技術
当社では、別項の「ディープラーニング(人工知能の設計)」の中で示したようなニューラルネットワークをXilinx社のZynqへ搭載するといった実績を積みながら、実装技術の獲得を進めています(Zynqを使ったシステムの開発については、「デジタル・ソフトの協調設計(Zynq・Intel SoC)」をご参照ください)。
軽量化への取り組み
ニューラルネットワークをZynqなどのターゲットデバイスへ搭載可能な形に軽量化するために、まずは高性能マシンと同じ精度で演算した場合に消費するリソースを見積もります。例えば、ニューラルネットワーク内の各係数を保持するのに必要なメモリ量(レジスタの大きさ)、主要な演算部をFPGAで実現する場合に必要なデジタル回路の規模(DFFやルックアップテーブルの量)などです。また並行して、いくつかの仮定を置いた上で、処理時間(レイテンシとスループット)を計算しておきます。CNN形式のニューラルネットワークにはデジタル回路で並列可能な積和演算が大量に存在しますので、処理時間は並列数(つまりデジタル回路の規模)とのトレードオフの関係になります。
リソースの検討
そして、見積もった数値を元に、ターゲットデバイスへ搭載するためにはリソースをどのくらい減らすべきかを検討します。特に、演算のビット幅をいくつにするかがポイントです。デジタル回路で並列化する場合、基本的には浮動小数点ではなく固定小数点にて演算を行いますので、まずはニューラルネットワークの演算を固定小数点化します。そして、固定小数点化した際に生じる、ニューラルネットワークの出力結果の誤差を確認します。例えば、道路画像から中央線を検出するニューラルネットワークの場合には、道路画像を固定小数点化したニューラルネットワークへ入力して中央線の位置情報を出力させます。
この値と、高性能マシンで行った浮動小数点の演算結果の差が、誤差に相当します。この誤差とビット幅から決まるリソース量のトレードオフ関係から、最終的にビット幅を決定します。
しかしながら、仕様の精度を満たすビット幅を実現するには、ターゲットデバイスに入りきらないほどのリソース量が必要になることもあります。その場合には、人工知能の設計のフェーズまで戻り、ニューラルネットワークの構成を見直してディープラーニングを再実施することになります。
この値と、高性能マシンで行った浮動小数点の演算結果の差が、誤差に相当します。この誤差とビット幅から決まるリソース量のトレードオフ関係から、最終的にビット幅を決定します。
しかしながら、仕様の精度を満たすビット幅を実現するには、ターゲットデバイスに入りきらないほどのリソース量が必要になることもあります。その場合には、人工知能の設計のフェーズまで戻り、ニューラルネットワークの構成を見直してディープラーニングを再実施することになります。
実装
リソース量と処理時間にめどが立ったら、具体的な実装に入ります。
Xilinx社のSDSoCのような高位合成ツールを使って、デジタル回路を生成します。生成されたデジタル回路のサイズやレイテンシが想定より大きくなり過ぎた場合には、人手でRTLを設計します。
Xilinx社のSDSoCのような高位合成ツールを使って、デジタル回路を生成します。生成されたデジタル回路のサイズやレイテンシが想定より大きくなり過ぎた場合には、人手でRTLを設計します。
高位合成ツール SDSoC
以上のように、具体的な実装フローは一般的なシステムの場合とほとんど変わりませんが、トレードオフ関係を理解して適切な判断を下すためには、実装の担当者が人工知能を理解していることが求められます。また、目標の性能が得られないことが分かった場合に、人工知能の設計のフェーズまで戻るかどうかの判断も、実装の担当者に委ねられる部分が大きくなります。