エッジデバイス実装
学習済みのアルゴリズムからターゲットHWに最適な処理アーキテクチャを設計し、エッジデバイスでの高速実行を実現。
お客さまが開発されたアルゴリズムをご提供いただくだけで、当社でその内容を読解し、アルゴリズムに適したアーキテクチャを考案します。Caffe・Keras・TensorFlow・PyTorchなど各種のフレームワークに対応します。 これまで数十年にわたって培ってきたデジタル回路設計・組み込みソフトウエア開発の経験から、お客さまの手を煩わせることなく、最適なソリューションを実現します。INDEX
エッジデバイス実装サービス
エッジ環境におけるFPGAやGPUといったデバイスにアルゴリズムを実装するためには、ターゲットデバイスの特徴やリソースを熟知した上で、アーキテクチャ設計や場合によってはネットワークの軽量化が必要になります。
当社では FPGA をはじめ、GPU(Jetson AGX Xavier)やAIチップとして注目されているTPU(Google TPU)、VPU(Intel Movidius Myriad X VPU)への実装経験を生かし、デバイス選定から実装までお客さまのニーズにお応えします。
軽量化したセマンティックセグメンテーションのネットワークをさまざまなエッジデバイスに実装したデモを紹介します。
当社では FPGA をはじめ、GPU(Jetson AGX Xavier)やAIチップとして注目されているTPU(Google TPU)、VPU(Intel Movidius Myriad X VPU)への実装経験を生かし、デバイス選定から実装までお客さまのニーズにお応えします。
軽量化したセマンティックセグメンテーションのネットワークをさまざまなエッジデバイスに実装したデモを紹介します。
デモ①:FPGA(Zynq UltraScale+)でセマンティックセグメンテーションの高速実行
USBカメラを入力にリアルタイムでセマンティックセグメンテーションを実行している様子を紹介します。
クラス一覧

クラス一覧
当社ではFPGAにセマンティックセグメンテーションのアルゴリズムを実装し、処理時間40fpsの高速化を達成しました。
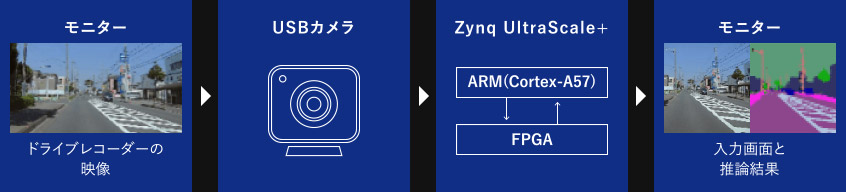

- モニターに表示したドライブレコーダーの映像をUSBカメラで取り込む
- ARM ⇒ FPGAへUSBカメラ画像を転送し、FPGAでセマンティックセグメンテーションの推論を行う
- FPGA ⇒ ARMへ推論結果を転送し、入力画像と共にモニターへ出力する
| 実装したアルゴリズムとターゲットデバイス |
|---|
| アルゴリズム:PixelNet(http://www.cs.cmu.edu/~aayushb/pixelNet/) ターゲットボード:ZCU102(Xilinx Zynq UltraScale+ ZU9EG 搭載) ※当社で、上記アルゴリズムを元に FPGA向けにネットワーク構成を変更し、再学習 詳細は「アルゴリズム設計:セマンティックセグメンテーション」をご参照ください。 |
| 処理時間 |
| 40fps |
| クラス数 |
| 22クラス(道路、白線、自動車、歩行者など) |
デモ②:軽量化PixelNetのエッジデバイス実装比較 ~Zynq(FPGA), Jetson(GPU), TPUの推論実行~
デモ①と同様の軽量化PixelNetをさまざまなエッジデバイスに実装して推論実行の様子を比較しました。
| エッジデバイス | ZCU102 | Jetson AGX Xavier | Coral Dev Board | Coral USB Accelerator |
|---|---|---|---|---|
| メーカー | Xilinx | NVIDIA | ||
| アクセラレーター | FPGA | GPU @ 1.4 GHz DL アクセラレータ | Edge-TPU | |
| 処理能力 | 11 + 5 TFLOPS (FP16) 22 + 10 TOPS (INT8) |
4TOPS | ||
| CPU | ARM Cortex-A53(4-core) | ARM v8.2 64-bit CPU (8-core) | ARM Cortex-A53(4-core) | |
| 実装時のデータ幅 | INT16 | FLOAT32 | INT8 | |
| 実機イメージ |  |
 |
 |
 |
デモ動画では、各エッジデバイスのSDカードに保存された画像を1枚ずつ読み出し、即時に推論を行っています。
各エッジデバイスについて紹介します。
各エッジデバイスについて紹介します。
ZCU102
Zynq UltraScale+ である ZU9EG というチップが載ったFPGAボードです。ARM と FPGA の SoC(System on Chip)構成です。
デモ動画では、リアルタイムでの処理を実現できました。これはFPGAに当社で検討した最適な処理アーキテクチャを実装し、処理速度40fpsでセグメンテーションを実行できたためです。
Jetson AGX Xavier
Nvidia社のGPUが載ったモジュールです。CPU として ARM が搭載されています。
デモ動画では、フレームワークにTensorFlowを使用し、GPUで推論を実行しました。
処理速度13~15fpsでセグメンテーションを実行できました。
Coral Dev Board
Google社のEdge TPUが載ったボードです。NXP i.MX 8M SoC と Edge TPUのSoM(System on Module)構成です。
デモ動画では、TensorFlow Liteへ変換したモデルを実装したEdge TPUで推論を実行しました。
処理速度17~20fpsでセグメンテーションを実行できました。
動画内のデモ画面がカクついているのは、NXP i.MX 8M に載っている ARM での描画処理が重いためです。
Coral USB Accelerator
Google社のEdge TPUを搭載したUSBアクセラレータです。デモ動画では、TensorFlow Liteへ変換したモデルを実装したEdge TPUで推論を実行しました。
USBアクセラレータであるため、入力画像の転送と推論結果の描画には他のデバイスが必要です。
デモ動画ではJetson nanoを使用しました。
処理速度8~10fpsでセグメンテーションを実行できました。
エッジデバイスへの実装工程の一例
デモ作成時のエッジデバイスへの実装工程を紹介します。以下の「アノテーション」「アルゴリズムの設計:軽量化」「再学習」「エッジデバイスへ実装」の工程は当社でトータルに行いました。
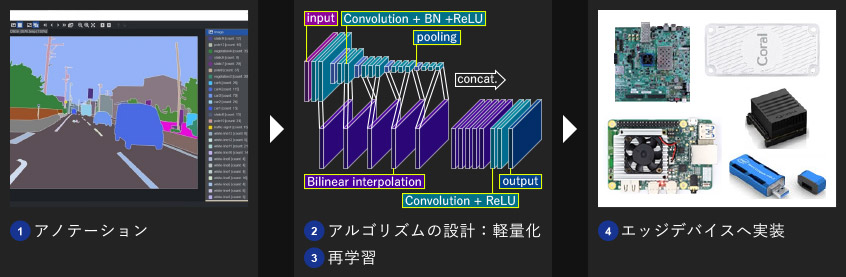
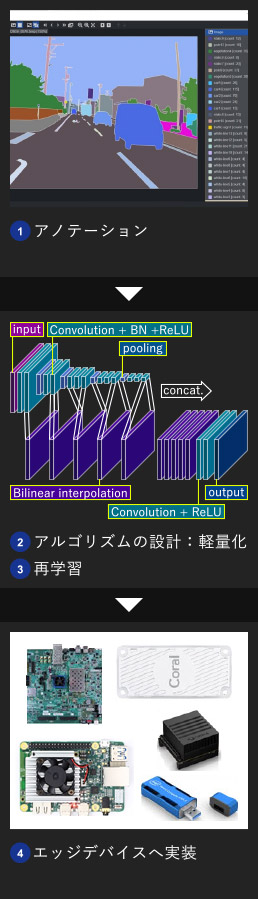
- デモでは当社で取得・アノテーションした浜松市内の道路画像を使用しました。
アノテーションサービスについては「アノテーション」をご参照ください。 - エッジデバイスへの実装のため、当社でPixelNetを独自に軽量化しました。
軽量化の詳細は「アルゴリズム設計:セマンティックセグメンテーション」をご参照ください。 - Pythonコードで軽量化したネットワークを再学習しました。
- デバイスごとにデータ幅などを調整し、各エッジデバイスへ実装しました。
エッジデバイスへの実装のポイントを次項目「エッジデバイスでの高速実行に向けた実装のポイント」で紹介します。
エッジデバイスでの高速実行に向けた実装のポイント
当社では、お客さまのご要望はもちろん、ターゲットとするデバイスやアルゴリズムに合わせて高速実行を実現する最適なアーキテクチャ設計を行います。例えば、FPGAへの実装のポイントとして、「パイプラインによるスループットの向上」や「各処理層の出力CH方向に並列化」などが挙げられます。
以下では、「パイプラインによるスループットの向上」をご紹介します。
下図のような Conv(3×3)→ Conv(3×3)→ MaxPooling(2×2)という CNN で考えると、
以下では、「パイプラインによるスループットの向上」をご紹介します。
下図のような Conv(3×3)→ Conv(3×3)→ MaxPooling(2×2)という CNN で考えると、
- 前段のConv1_1から3行分の特徴量が出力されたら、次段の Conv1_2 の処理を開始する
- MaxPoolingでも同様にConv1_2 から2行分の特徴量が入力されたら処理を開始する

開発実績
姿勢推定
顧客開発のアルゴリズムをZynqへ実装し、エンドユーザー様向けのデモシステムを開発。汎用物体検出
SDSoC(Xilinx製 高位合成ツール)での実装環境の開発および Zynqへ初期実装。車載向け領域分割
セグメンテーションを行うアルゴリズムを FPGA、TPU、VPUをターゲットにデプロイ検討。開発フロー
-
01
学習済みアルゴリズム(お客様ご提供) -
02
デバイス選定 -
03
アーキテクチャ設計 -
04
コード作成・検証 -
05
実機にて動作確認(処理時間など)
01学習済みアルゴリズム(お客様ご提供)
アルゴリズム開発は、当社でも設計サービスを行っています。 お客さまが抱えている課題・ご要望に応じて、アルゴリズムの検討・設計から対応することも可能です。
02デバイス選定
コスト、消費電力などお客さまのご要望に応じて、最適なデバイスをご提案します。
03アーキテクチャ設計
デバイスの特徴を理解し、ロジックリソースなどを概算しながら、所望の処理時間となるようアーキテクチャを設計します。場合により、デバイス実装に向けたネットワークの軽量化検討も行います。
例)ボトルネックとなる処理の抽出など
例)ボトルネックとなる処理の抽出など
04コード作成・検証
検討したアーキテクチャとなるようコードを作成し、作成後はツール上でロジックリソース使用率や処理時間の概算および等価性検証(期待値比較)を実施します。 アーキテクチャの再検討 ⇔ コード修正・検証 のイタレーションを行いながら、ターゲットデバイスへの実装を目指します。
05実機にて動作確認(処理時間など)
ツールでビルドしたコードを実機に実装し、実機での処理時間や精度を評価します。
パートナー

三栄ハイテックスは Lattice 社認定の sensAI 設計サービス提携企業です

三栄ハイテックスは AMD のアダプティブコンピューティングパートナーです